|
转自【新智元导读】
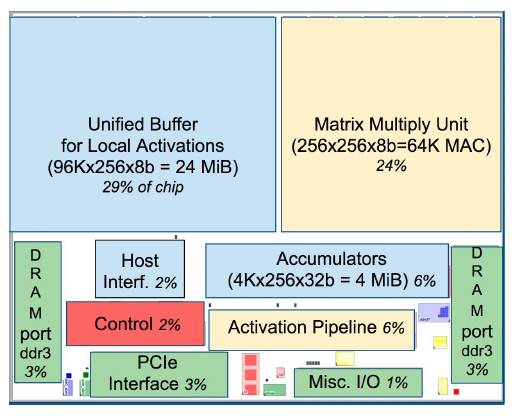
谷歌公布 TPU 论文(被ISCA-17 接收)引发新一轮讨论,连英伟达CEO黄仁勋都亲自撰文回应。使用 TPU 代表了谷歌为其人工智能服务设计专用硬件迈出的第一步,为特定人工智能任务制造更多的专用处理器很可能成为未来的趋势。TPU 推理性能卓越的技术原理是什么,TPU 出现后智能芯片市场格局又会出现哪些变化?中国在智能芯片市场上的位置如何? 中科院计算所研究员包云岗指出,计算机体系结构旗舰年会ISCA是各大公司展示硬实力的舞台,每年的关键技术对信息产业的推动作用不容忽视。寒武纪创始人兼CEO陈天石指出,需要密切注意谷歌 TPU 给智能领域带来的新生态,“是与之融合,还是与之抗衡,是每个芯片公司需要考虑的问题”。 如果说现在是 AI 走出实验室,走进三百六十行纷纷落地的时代,那么支撑这场技术应用大浪潮的背后,正是芯片、硬件行业的茁壮发展和惨烈竞争。要将一款芯片研发出来并且推向市场,需要几十亿乃至几百亿美元的巨资,更不用说这伴随的人力资源和研发时间。很多的项目都死掉了。而把握住并且乘上了深度学习这股浪潮的 GPU 巨头英伟达,现在是以季度乃至月为单位往外推出新品,其速度和效率令人咂舌。GPU 在深度学习市场势不可挡。 上周,谷歌公布了张量处理器(TPU)的论文——TPU 已经在谷歌数据中心内部使用大约两年,而且TPU 在推理方面的性能要远超过 GPU(“尽管在一些应用上利用率很低,但 TPU 平均比当前的 GPU 或 CPU 快15~30倍,性能功耗比高出约 30~80 倍”)——不啻一块巨石,在业内激起了又一波围绕深度学习专用加速器的热浪。TPU 的出现以及谷歌研发芯片这一举动本身,都对整个智能产业有着深远的意义。 任何一款新的芯片都值得我们关注,因为这影响着千千万万的应用和使用这些应用人。下面,我们从谷歌 TPU 的诞生讲起,全面回顾这款芯片及其出现在智能领域代表的新的趋势和重要意义。 TPU 诞生:从谷歌决定自己打造更高效的芯片说起 2011年,Google 意识到他们遇到了问题。他们开始认真考虑使用深度学习网络了,这些网络运算需求高,令他们的计算资源变得紧张。Google 做了一笔计算,如果每位用户每天使用3分钟他们提供的基于深度学习语音识别模型的语音搜索服务,他们就必须把现有的数据中心扩大两倍。他们需要更强大、更高效的处理芯片。 他们需要什么样的芯片呢?中央处理器(CPU)能够非常高效地处理各种计算任务。但 CPU 的局限是一次只能处理相对来说很少量的任务。另一方面,图像处理单元(GPU) 在执行单个任务时效率较低,而且所能处理的任务范围更小。不过,GPU 的强大之处在于它们能够同时执行许多任务。例如,如果你需要乘3个浮点数,CPU 会强过 GPU;但如果你需要做100万次3个浮点数的乘法,那么 GPU 会碾压 CPU。 GPU 是理想的深度学习芯片,因为复杂的深度学习网络需要同时进行数百万次计算。Google 使用 Nvidia GPU,但这还不够,他们想要更快的速度。他们需要更高效的芯片。单个 GPU 耗能不会很大,但是如果 Google 的数百万台服务器日夜不停地运行,那么耗能会变成一个严重问题。 谷歌决定自己造更高效的芯片。 TPU 首次公开亮相,号称“把人工智能技术推进 7 年” 2016年5月,谷歌在I/O大会上首次公布了TPU(张量处理单元),并且称这款芯片已经在谷歌数据中心使用了一年之久,李世石大战 AlphaGo 时,TPU 也在应用之中,并且谷歌将 TPU 称之为 AlphaGo 击败李世石的“秘密武器”。 作为芯片制造商的大客户,谷歌揭幕 TPU 对 CPU 巨头英特尔和 GPU 巨头英伟达来说都是不小的商业压力。为了适应市场趋势,英特尔和英伟达都在去年分别推出了适用于深度学习的处理器架构和芯片意欲扩张当下的市场份额,但看来“专用芯片”的需求比他们预计还要更深。 不仅如此,单是谷歌自己打造芯片的这一行为,就对芯片制造商构成了巨大影响。尤其是谷歌基础设施副总裁 Urs Holzle 在 2016 年的发布会上表示,使用 TPU 代表了谷歌为其人工智能服务设计专用硬件迈出的第一步,今后谷歌将设计更多系统层面上的部件,随着该领域逐渐成熟,谷歌“极有可能”为特定人工智能任务制造更多的专用处理器。 当时,Holzle 对 TechCrunch 记者说:“有些时候 GPU 对机器学习而言太通用了。” 显然,面向机器学习研发专用的处理器已经是芯片行业的发展趋势。 2016年谷歌首次公开TPU时给出的图片,当时出于保密考虑,关键部分都盖着散热片,看不出具体设计。 当时,TPU 团队主要负责人、计算机体系结构领域大牛 Norm Jouppi 介绍,TPU 专为谷歌 TensorFlow 等机器学习应用打造,能够降低运算精度,在相同时间内处理更复杂、更强大的机器学习模型并将其更快投入使用。Jouppi 表示,谷歌早在 2013 年就开始秘密研发 TPU,并且在一年前将其应用于谷歌的数据中心。2016年 TPU 消息刚刚公布时,Jouppi 在 Google Research 博客中特别提到,TPU 从测试到量产只用了 22 天,其性能把人工智能技术往前推进了差不多 7 年,相当于摩尔定律 3 代的时间。 在公布自行设计 TPU 芯片时,Google 并没有透露更多有关芯片架构或功能的信息,所以引发了许多猜测。上周,谷歌终于公开了 TPU 的论文,我们也终于得以了解 TPU 的技术细节。当然,这也掀起了新一轮的讨论热潮。 TPU 重磅论文解密架构设计,75 位联合作者,“能效比CPU/GPU 高30~80倍” 谷歌上周公布的 TPU 论文《在数据中心分析中对张量处理器性能进行分析》。论文联合了一共 75 位作者,由大牛 Norman Jouppi 领衔,堪称“重磅”。 摘要 许多架构师认为,现在只有领域定制硬件(domain-specific hardware)能带来成本、能耗、性能上的重大改进。本研究评估了自2015年以来部署在各数据中心,用于加速神经网络(NN)的推理过程的一种定制 ASIC 芯片——张量处理器(TPU)。TPU 的核心是一个65,536的8位矩阵乘单元阵列(matrix multiply unit)和片上28MB的软件管理存储器,峰值计算能力为92 TeraOp/s(TOPS)。与CPU和GPU由于引入了Cache、乱序执行、多线程和预取等造成的执行时间不确定相比,TPU 的确定性执行模块能够满足 Google 神经网络应用上 99% 相应时间需求。CPU/GPU的结构特性对平均吞吐率更有效,而TPU针对响应延迟设计。正是由于缺乏主流的CPU/GPU硬件特性,尽管拥有数量巨大的矩阵乘单元 MAC 和极大的偏上存储,TPU 的芯片相对面积更小,耗能更低。 我们将 TPU 与服务器级的 Intel Haswell CPU 和 Nvidia K80 GPU 进行比较,这些硬件都在同一时期部署在同个数据中心。测试负载为基于 TensorFlow 框架的高级描述,应用于实际产品的 NN 应用程序(MLP,CNN 和 LSTM),这些应用代表了我们数据中心承载的95%的 NN 推理需求。尽管在一些应用上利用率很低,但 TPU 平均比当前的 GPU 或 CPU 快15~30倍,性能功耗比(TOPS/Watt)高出约 30~80 倍。此外,在 TPU 中采用 GPU 常用的 GDDR5 存储器能使性能TPOS指标再高 3 倍,并将能效比指标 TOPS/Watt 提高到 GPU 的 70 倍,CPU 的 200 倍。 也就是在这篇论文中,谷歌公布了第一代 TPU(谷歌于 2015 年就在其数据中心部署)的设计图及其他细节。 谷歌上周公布的论文中,给出了第一代 TPU 的电路板细节。可以插入服务器的一个SATA盘位中,但卡使用的是PCIEGen3x16连接。 TPU 模块图。主要的计算部件是右上角的黄色矩阵乘单元。输入是蓝色的权重数据队列FIFO和蓝色的统一缓冲(Unified Buffer),输出是蓝色的累加器(Accumulators)。黄色的激活单元在累加之后执行非线性函数,然后数据返回统一缓冲区。 TPU晶圆的布局规划。形状与图1中一致。亮(蓝)色的数据缓冲占据晶圆面积的37%,亮(黄)色的计算部分占据30%,中(绿)色I/O部分占10%,而暗(红)色的控制仅占2%。控制部分在CPU或者GPU中都比TPU更大(并且也更难设计)。 谷歌称 TPU 为张量处理单元,专为 TensorFlow 定制设计,TensorFlow 是 Google 的一个开源机器学习软件库。 这篇论文将第一代的 TPU 与部署在 Google 的相同数据中心的服务器级 Intel Haswell CPU 和 Nvidia K80 GPU 进行了性能对比。由于 TPU 是专为推理投产一个定制的ASIC芯片(并购买市售的GPU用于训练),因此论文中的性能比较也仅限于推理操作。 关于“推理”和“训练”两者之间的关联,我们可以看论文里的解释: 神经网络的两个主要阶段是训练(Training或者学习Learning)和推理(inference或者预测Prediction),也可以对应于开发和产品阶段。开发人员选择网络的层数和神经网络类型,并且通过训练来确定权重。实际上,当前的训练几乎都是基于浮点运行,这也是GPU为何如此流行的原因之一。一个称为量化(quantization)的步骤,将浮点数转换为很窄仅使用 8 个数据位的整数,对推理过程通常是足够了。8 位的整数乘法比IEEE 754标准下16位浮点乘法降低 6 倍的能耗,占用的硅片面积也少 6 倍;而整数加法的收益是13倍的能耗与38倍的面积。 TPU(蓝线)、GPU(红线)和 CPU(金线)的性能功耗比。 论文在速度和效率两方面进行了比较。速度以存储带宽函数每秒执行的 tera-操作测量。TPU 比 CPU 和 GPU 快 15~30 倍。效率则以每瓦特能量消耗执行的 tera-操作计算。TPU 比 CPU 和 GPU 效率高 30~80 倍。 TPU,GPU,CPU 和改进的 TPU 的性能对比。 GPU(蓝色)和TPU(红色)相对于CPU的能效比(功耗/瓦,TDP),以及 TPU 相对于GPU 的能效比。TPU’是改进的TPU。绿色代表改进的 TPU 与 CPU 对比的性能,浅紫色代表改进的 TPU与 GPU 对比性能。总和数据(Total)包含了主机服务器的功耗,增量数据(Incremental)则不包含主机服务器的功耗。GM 和 WM 是几何与加权平均数据。 对硬件研究的启示:软硬件协同开发可能进一步提升设计门槛 新智元转载了 NUDT 研究组对 TPU 论文的专业分析,文章以论文《在数据中心中对张量处理器进行性能分析》为基础,从专业的角度总结了一些启示。 现在我们引用如下: 底层硬件设计,特别是以处理器设计为代表的研发工作门槛并未降低。但由于无论专用和通用处理器都需要得到最终用户的认可,考虑软件的真实需求,软硬件协同开发可能进一步提升设计门槛。(即:硅码农还是有市场需求的) 相比于神经网络模型、软件框架和应用的当前的进化速度,传统ASIC半定制或者全定制的开发周期和速度难以加速。但仍然有可能保持专用设计一定的寿命,并通过性能模型评估确定改进方案。(即:研发还是老套路,但会更困难。要硅马跑得快又少吃草或最好不吃草的情况只会恶化) 真实应用的部署和数据收集是必需的,而且有极强的说服力,当然最终目的是获得处理器目标用户的认可。(即:总有人能做出叫好又叫座的设计,有足够资源配合可能性更高些) 。在论文发布之前,甚至在初步阅读论文时很多评论表示,TPU设计没有细节,连照片都盖着散热片。但仔细阅读论文能看到,Google在2015年就提交了相关的论文申请,在AlphaGO下棋的时候就可以通过专利局网站看到相关专利了。(即:先进商业公司和上市公司的知识产权保护,购并和调查并非是装样子的。) 专业知识,仍然是一切的基础。包括TPU计算核心:由65536个乘法器构成的256x256矩阵单元,其脉动执行 Systolic Execution 都能够追溯到1984年哈佛大学研究人员在TOC上发表的论文。在NUDT求学过的应该很容易联想起向量、行波流水等概念。(即:学习和专业知识的储备依然有价值)
专家看法:要注意谷歌 TPU 给智能领域带来的新生态 中科院计算所研究员包云岗撰文评论称: 一、计算机体系结构和算法是信息技术进步的两大引擎。过去40年处理器性能提升了1,000,000倍,单台计算机内存容量增长了1,000,000,000倍。这是什么概念,上世纪70年代语音识别算法只能放几十个单词的语音到内存中进行训练,但今天可以成千上万人的几十亿个单词的语音放到内存中进行训练。大数据需要大处理能力。 二、处理器体系结构研究有时会显得很神奇,同样的算法、同样的晶体管,不同的组织方式性能就会让算法运行起来有几十到几百倍的差别。有时又会显得很无奈,使劲优化也只能提升1%的性能。但不管如何,处理器终究还是“大国重器”或“贵司重器”,这是知识密集型和资本密集型的活,不是一般公司可以玩得起,搞得敢做体系结构研究的人也越来越少。如何建起人才培养生态、吸引更多学生加入体系结构研究,需要业界更多支持。 三、计算机体系结构旗舰年会ISCA每年只录50篇左右论文,但对信息技术的推动作用不容忽视,成为各大公司展示硬实力的舞台——微软在2014年ISCA上发表其FPGA在数据中心应用的论文,引领全世界一波FPGA热潮;Google 则是在今年ISCA上公布张量处理器TPU细节;而10年前则有D.E. Shaw在2007年ISCA上发表了其黑科技——分子动力学专用机Anton;而国内计算所也是在2016年ISCA首次发布了面向神经网络处理器的寒武纪指令集。 寒武纪创始人兼CEO陈天石在接受新智元专访时称: 一、谷歌 TPU 肯定还会继续做下去 在TPU的ISCA2017论文中,Google引用了DianNao全系列学术论文外加ACM旗舰杂志Communications of the ACM刊登的DianNao系列综述,同时还专门用英文注释这几个名字的含义(Big computer, general computer, vision computer),对我们前期工作显示了相当的尊重。Google还引用了寒武纪团队发表的Cambricon指令集论文(国际上首个智能处理器指令集),从侧面反映Google同行一直在跟踪我们最新的工作。 Google TPU未来肯定还会继续做下去。我们的早期学术合作者Olivier Temam教授在几年前加入了Google,许多业界的朋友猜测未来DianNao系列的学术思想会与TPU发生某种程度的融合。我们对此乐见其成,也非常期待与国际同行在这一领域同场竞技。 二、脉动阵列架构使 TPU 处理卷积比较高效,但 TPU 性能做到极致还有距离 脉动阵列架构处理卷积会比较高效,但在其他一些workload上效率可能又不大好。因此从效率角度说,TPU的性能离做到极致还有距离。TPU的优秀性能与其采用了8位运算器是分不开的。这样做可以使单位面积的芯片能摆放更多的运算器,对内存带宽的需求也大大降低,这使得TPU获得了很好的绝对性能。当然,降低运算器的位宽并不是提升性能、降低面积功耗的唯一办法。稀疏化神经网络是另外一条道路。在稀疏神经网络中,由于模型每层的稀疏度可以在[0,1]连续区间变化,这使得整个模型的识别精度和模型的运算/访存量之间的tradeoff是连续可控的。相比之下,直接把模型降到8位,可能会带来不可控的识别精度丢失。当前深度学习发展日新月异,我们认为应对两种思路兼容并包。 三、应用层面的深刻变化催生了当前这一轮芯片的百花齐放 Google 这样的公司,从最开始使用 CPU 这样的通用芯片,过渡到 GPU 与 FPGA,但是FPGA无法提供想象的速度,又再过渡到专属的 ASIC来面对应用的需求。而Facebook 走的是全GPU路线,微软在开发 FPGA。每个厂商肯定都不会把鸡蛋放在一个篮子里。例如Google虽然自己做了TPU,但肯定还是会大量采购CPU和GPU。目前这一轮芯片的百花齐放其实根源是应用层面发生了深刻的变化。未来待应用层面相对稳定以后,芯片的定位和市场会进入一个稳定期。 Google应该主要是将TPU应用于人工智能云服务,而不会直接出售TPU。对于芯片领域的创业公司来说,不用太担心Google会直接抢饭碗,但是需要密切注意TPU给智能领域带来的新生态。是与之融合,还是与之抗衡,是每个芯片公司需要考虑的问题。 关于泛AI领域,中国的成就有目共睹。这里我更想说一说处理器这块(也呼吁社会各界给予更多关注):目前我国的处理器架构领域学术和工程水平不断提高,在许多方向上(不光是智能处理器这块)已经和国际同行难分伯仲。例如通用CPU这块,我们国内有龙芯、申威、飞腾,有兆芯和海光,也有华为海思这样的民企,已经是百花齐放。我坚信国内同行的共同努力最终一定会带动我国整个处理器行业的跨越式发展,在未来进一步解决了工艺瓶颈后,一定可以做到和美国并驾齐驱。 英伟达黄仁勋亲自撰文将最新GPU与TPU对比,表示不服反被吐槽 有趣的是,英伟达 CEO 黄仁勋昨天亲自在官博发表署名文章,将 TPU 和英伟达的最新品 P40 做了比较——尽管外界都已经意识到,TPU 论文里没有将第一代 TPU 跟英伟达最新款的 GPU 做比较,但黄仁勋显然还是忍不住。 黄仁勋文章的结果是,英伟达 Tesla P40 在 GoogleNet 推断任务中的性能是 Google TPU 的 2倍。不仅如此,P40 的带宽也是 TPU 的十倍还多。 但是,这篇文章并没有如想象中那样“更新”GPU与 TPU 的性能,而是引来了各界的无情吐槽。在Twitter、Reddit 和 HackerNews 等技术网站,网友纷纷指出,首先,相同情况下,TPU 的能耗是 75W,而 P40 的能耗是 250W。此外,谷歌论文里的是第一代 TPU(2015 年部署在谷歌数据中心),现在肯定已经升级好几代了——黄仁勋用最新 GPU与第一代TPU对比,GPU性能更优也无疑是必然的结果。 不过,黄仁勋在文章里指出的以下几点值得注意: “虽然Google和NVIDIA选择了不同的开发道路,但我们的方法中还是有一些共同点。特别是: TPU 是深度学习的未来吗? 鉴于深度学习近年来强劲的影响力,连《福布斯》这样的大众媒体都对谷歌TPU 进行了分析报道,作者 Kevin Murnane 指出,论文中给出的这些对比的数字非常厉害,但是必须注意以下几点,才能说 TPU 是深度学习的未来。 首先,Google 在测试中使用的是 2015年初生产的芯片。自那以后 Nvidia 和 Intel 都对自己的芯片进行了升级改进,因此与现在的芯片比较结果会怎样我们还无法知道。不过,尽管如此,两年前 TPU 的优势就已经如此巨大,Intel 和 Nvidia 不大可能把这个差距完全消除。 还有一个更重要的考虑因素是芯片性质的比较。Intel 的 CPU 是专为灵活性设计的通用芯片,一次运行的进程数量有限。Nvidia 的 GPU 是专为一次运行许多神经网络计算设计的通用芯片。而 Google 的 TPU 是专门用于在 TensorFlow 中执行特性功能的 ASIC(专用集成电路)。 CPU 的灵活性最大,它可以运行各种各样的程序,包括使用各种软件库的深度学习网络执行的学习和推理。GPU 不像 CPU 那样灵活,但它在深度学习计算方面更好,因为它能够执行学习和推理,并且不局限于单个的软件库。该测试中的 TPU 则几乎没有灵活性。它只能在 TensorFlow 中执行推理,但它的性能非常好。 早期的生成深度学习网络 深度学习计算中的芯片部署都不是零和博弈。现实世界的深度学习网络需要系统的 GPU 与其他 GPU 或诸如 Google TPU 之类的 ASIC 通信。GPU 是理想的工作环境,具有深度学习所需的灵活性。但是,当完全专用于某个软件库或平台时,则 ASIC 是最理想的。 谷歌的 TPU 显然符合这样的要求。TPU 的卓越性能使得 TensorFlow 和 TPU 很可能是一起升级的。虽然谷歌官方已经多次明确表示,他们不会对外销售 TPU。不过,利用 Google 云服务做机器学习解决方案的第三方可以得益于 TPU 卓越性能的优势。 智能芯片市场格局一变再变,谷歌 TPU 的出现让面向神经网络/深度学习特定领域加速的芯片趋势更加明显。高端 AI 应用需要强大的芯片做支撑。软硬件缺了哪一块中国的智能生态也发展不起来。中国处理器学术和工程都在不断提高,我们期待中国芯早日出现在世界舞台与国际同行竞技。 参考资料 包云岗,《说点Google TPU的题外话》 CPUinNUDT,《基于论文,对谷歌 TPU 的最全分析和专业评价》 https://www.forbes.com/sites/kevinmurnane/2017/04/10/the-great-strengths-and-important-limitations-of-googles-machine-learning-chip/#2ff4fbca259f https://blogs.nvidia.com/blog/2017/04/10/ai-drives-rise-accelerated-computing-datacenter/
3月27日,新智元开源·生态AI技术峰会暨新智元2017创业大赛颁奖盛典隆重召开,包括“BAT”在内的中国主流 AI 公司、600多名行业精英齐聚,共同为2017中国人工智能的发展画上了浓墨重彩的一笔。 访问以下链接,回顾大会盛况:
| 
 窥视卡
窥视卡 雷达卡
雷达卡

 发表于 2017-4-17 14:32:26
发表于 2017-4-17 14:32:26











 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜






